Regard rétrospectif et cliométrique sur une étape de la construction européenne – Les activités innovantes : 1981-2001
Claude Diebolt, CNRS et Université de Strasbourg (BETA)
L’objet de cet article est d’étudier les débordements géographiques de connaissance sur l’activité innovante et le processus de convergence des régions européennes de 1981 à 2001. Notre recherche révèle la présence d’effets spatiaux que nous intégrons successivement dans notre analyse de la convergence. L’estimation d’un modèle avec autocorrélation spatiale des erreurs montre que les effets de débordement géographique contribuent favorablement au processus de rattrapage des régions les moins performantes. Nous modélisons l’hétérogénéité spatiale par une spécification à deux régimes spatiaux, de type « centre-périphérie ». L’ensemble de ces résultats montrent que le processus de convergence globale masque des disparités au sein des régions européennes où, sur la période considérée, seules convergent les régions appartenant au centre de l’Europe.
Codes JEL : C21, N90, N94, O33, O52, R11.
Mots-clefs : brevets, cliométrie, convergence des économies européennes, effets spatiaux, persistance, régions européennes.
Citer cet article
Claude Diebolt « Regard rétrospectif et cliométrique sur une étape de la construction européenne – Les activités innovantes : 1981-2001 », Bulletin de l’Observatoire des Politiques Économiques en Europe, vol. 46, 5 - 17, Eté 2022 : Spécial « 50 ans du BETA ».
Introduction
Cette contribution cliométrique (Diebolt 2016, Diebolt et Haupert 2019) analyse l’activité innovante des régions européennes sur la période 1981-2001. Elle se situe en prolongement de précédentes publications consacrées à la dynamique structurelle et spatiale des systèmes de brevets d’une part (cf. plus particulièrement Diebolt et Pellier 2020), au capital humain dans les régions européennes d’autre part (cf. notamment le récent ouvrage de Diebolt et Hippe 2022).
Nous appliquons les méthodes de l’analyse exploratoire des données spatiales aux demandes de brevets par million d’habitants déposées à l’Office européen des brevets (OEB) afin de visualiser les distributions spatiales, détecter les schémas d’association spatiale, identifier les localisations atypiques ou encore suggérer certaines formes d’hétérogénéités spatiales (Anselin 1988). Notre analyse repose sur la statistique $$$I$$$ de Moran pour la mesure d’une autocorrélation de type globale et sur le diagramme de Moran complété par les indicateurs locaux d’association spatiale pour la mesure d’une autocorrélation de type locale.
Les données, extraites de la base REGIO d’Eurostat, concernent 131 régions pour 12 pays de l’union européenne sur la période 1981-2001 : le Danemark (1), l’Irlande (1), le Luxembourg (1), l’Espagne (6 régions, les îles Canaries sont exclues), le Royaume-Uni (10), l’Autriche (9), la Belgique (11 régions), l’Allemagne (30 régions, les régions de l’Allemagne de l’Est sont exclues pour des raisons historiques), la France (22), les Pays-Bas (12), la Suède (6). Pour notre analyse, nous avons privilégié le niveau 2 de la Nomenclature des unités territoriales statistiques [1] puisqu’il est considéré par les autorités européennes comme le cadre utilisé par les états membres pour l’application de leurs politiques régionales d’innovation. Toutefois, l’absence de disponibilité des données pour certaines régions de l’Espagne et du Royaume-Uni nous contraint à choisir le niveau Nuts 1 pour ces deux pays. Les régions d’Ecosse et de Londres (Royaume-Uni), de Smaland med öarna et de Västsverige (Suède) sont exclues par manque de disponibilité des données. Nous excluons également les îles Canaries (Espagne) et les Dom-Tom (France) en raison de leur éloignement géographique.
Nous choisissons les demandes de brevets déposées à l’Office européen des brevets comme une mesure de l’output d’innovation au niveau régional [2]. Même si le brevet est un indicateur partiel de l’innovation, il représente néanmoins une source importante de connaissances codifiées et constitue l’un des canaux possibles de la diffusion du savoir technologique. Les demandes de brevets déposées auprès l’Office européen des brevets (OEB) sont comptabilisées par année de priorité. Les statistiques concernent à la fois les demandes directes et les demandes déposées en vertu du traité de coopération en matière de brevets (TCB) désignés par l’OEB. La répartition régionale des demandes de brevets s’effectue selon le lieu de résidence de l’inventeur, ce qui est préférable pour localiser précisément chaque innovation. Dans le cas où une demande mentionne plusieurs inventeurs, elle est répartie en parts égales entre tous les inventeurs et entre leurs régions, ceci afin d’éviter les doubles comptages. Pour notre recherche, les tests sont effectués sur le ratio brevet/million d’habitants, les séries étant exclusivement calculées à partir des données de la base REGIO.
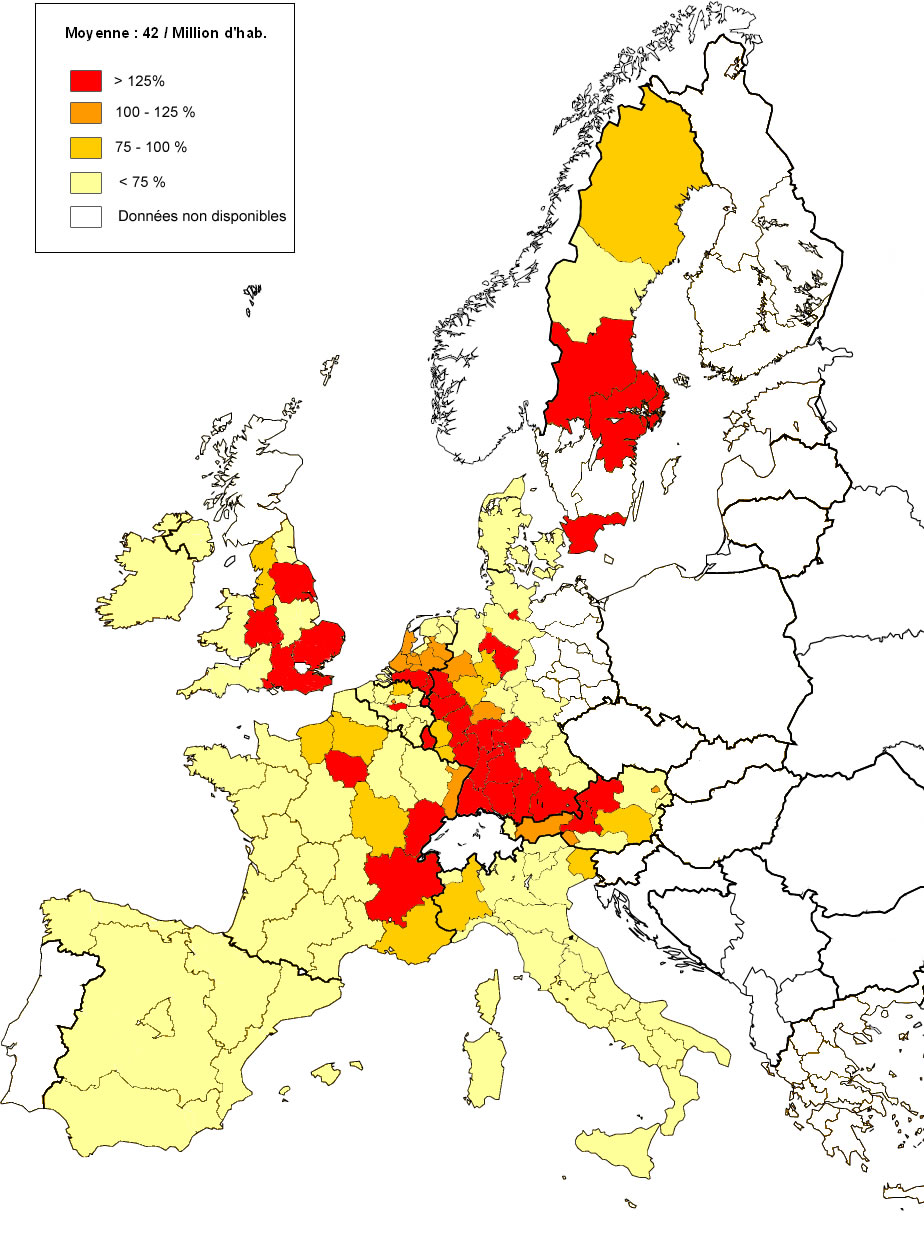
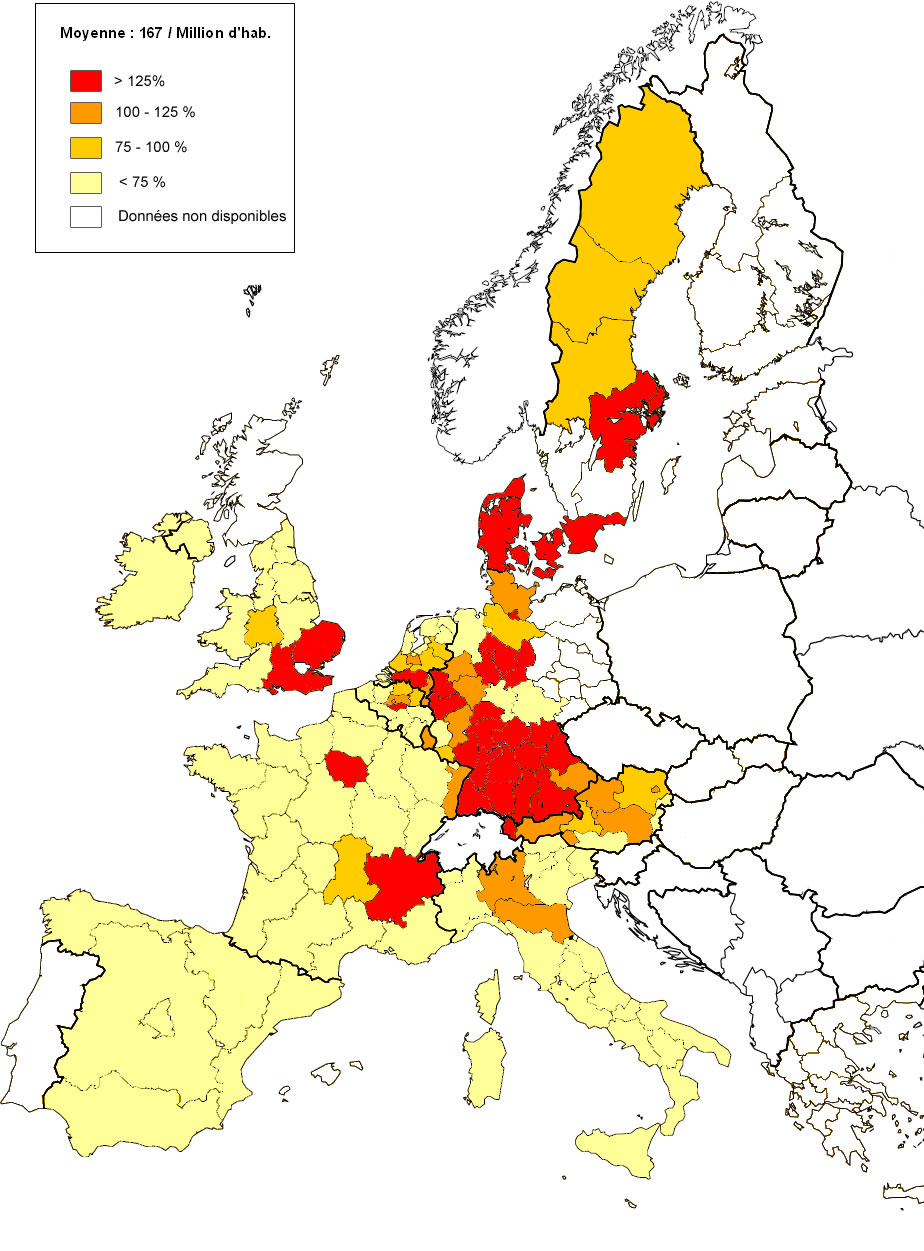
Les cartes en annexe A.1 et A.2 représentent la distribution régionale des demandes de brevets par million d’habitants. En 1981, la production d’innovations n’est pas répartie de manière homogène dans l’espace européen, ce qui traduit une forte disparité entre les régions mais également entre les pays. Un clivage de type centre-périphérie semble d’ailleurs dominer. Les régions les plus performantes sont regroupées en majorité au centre de l’Europe (régions de l’Allemagne de l’ouest, de l’Autriche, le Luxembourg, quelques régions des Pays-Bas et de l’est de la France). Quelques régions du nord de l’Europe sont également très performantes, il s’agit des régions localisées au sud du Royaume-Uni et de la Suède. Les régions déposant peu de demandes sont localisées majoritairement en périphérie de l’Europe : Espagne, sud de l’Italie, quelques régions françaises, nord du Royaume-Uni. Globalement, ce schéma est persistant en 2001 car les régions se répartissent selon les mêmes proportions qu’en 1981. Néanmoins, il est à noter que la production d’innovations a considérablement augmentée au cours de la période étudiée. La moyenne européenne des brevets par million d’habitants a quasiment quadruplée [3] (42 brevets/million hab. en 1981 contre 167 brevets/million hab. en 2001). Ces cartes fournissent une approche générale de la répartition des demandes de brevets mais n’indique en aucun cas si cette concentration spatiale des activités d’innovation génère un processus de dépendance spatiale. C’est à cette fin que les méthodes développées pour l’analyse exploratoire des données spatiales (AEDS) sont mobilisées.
1. Méthodologie cliométrique
1.1 La matrice de pondération spatiale
Notre analyse de l’interaction entres unités spatiales est basée sur une matrice de poids, d’une part destinée à modéliser l’interdépendance spatiale entre les observations de l’espace étudié et d’autre part à fixer une limite géographique à la diffusion des externalités. On définit une matrice de poids $$$W$$$ comme une matrice carrée, ayant autant de ligne et de colonne qu’il existe de régions. Chaque terme $$$w_{ij}$$$ de la matrice représente la façon dont les régions $$$i$$$ et $$$j$$$ sont connectées spatialement. Par convention, les éléments situés sur la diagonale de la matrice sont nuls. Il existe plusieurs types de matrices de poids telles que les matrices simples de contiguïté reposant sur l’existence de frontières communes ou des matrices de distance seuil fondées sur le nombre des $$$k$$$ plus proches voisins ou encore sur la distance sphérique entre les centroïdes régionaux. Ces dernières matrices sont utiles pour définir une certaine distance à partir de laquelle on admet qu’il n’existe pas de dépendance spatiale entre deux unités spatiales. Dans cette étude, nous préférons utiliser une matrice de poids $$$W$$$ basée sur la distance sphérique entre les centroïdes des régions européennes. L’intérêt de cette matrice de distance est qu’elle assure les connections spatiales du Royaume-Uni au continent Européen. Par ailleurs, le fait qu’elle contienne exclusivement des distances géographiques garantit son exogénéité (Anselin et Bera 1998). Sa forme fonctionnelle est l’inverse de la distance au carré :
où $$$w_{ij}^*$$$ est un élément de la matrice de poids $$$W$$$ non standardisée, $$$w_{ij}$$$ un élément de la matrice de poids standardisée et $$$d_{ij}$$$ est la distance sphérique entre les centroïdes des régions $$$i$$$ et $$$j$$$. $$$D(k)$$$ représente la distance limite au-delà de laquelle les interactions sont supposées négligeables. Par définition, $$$D(1)=Q1$$$, $$$D(2)=Q2$$$ et $$$D(3)=Q3$$$ où $$$Q1$$$, $$$Q2$$$ et $$$Q3$$$ sont respectivement le premier quartile, la médiane et le troisième quartile de la distribution des distances sphériques. Nous définissons ainsi trois matrices de poids correspondant à ces trois distances seuils : $$$D(1) = 273$$$ miles (439 km), $$$D(2)= 462$$$ miles (743 km) et $$$D(3)= 711$$$ miles (1144 km).
Avec ce type de spécification, l’intensité des interactions entre les unités spatiales est corrélée négativement avec la distance qui les sépare. Les éléments de cette matrice sont standardisés tel que la somme de chaque ligne est égale à 1. Ainsi, c’est la distance relative et non absolue qui est prise en compte.
1.2 Test d’autocorrélation spatial globale
L’autocorrélation spatiale évalue le degré de corrélation des valeurs d’une variable aléatoire lié à la disposition géographique des données (Cliff et Ord 1981). Elle est dite positive lorsque des observations similaires (faibles ou élevées) sont regroupées géographiquement ; elle est dite négative lorsqu’une concentration spatiale d’observations dissemblables est observée. Dans le cas où la répartition spatiale des observations est aléatoire, on conclura à une absence d’autocorrélation. De manière générale, l’autocorrélation spatiale survient lorsque les données sont affectées par des processus qui relient des lieux différents, comme les processus d’interaction et de diffusion spatiale, les effets de débordement géographiques, etc. Dans certains cas, elle peut être causée par une mauvaise spécification du modèle liée à des erreurs de mesure ou bien à l’omission de variables spatialement autocorrélées (Le Gallo 2002).
La détection de l’autocorrélation spatiale globale s’effectue à partir de la statistique $$$I$$$ de Moran (Cliff et Ord 1981) qui s’écrit sous la forme matricielle suivante :
où $$$S_0$$$ est le facteur de standardisation égal à la somme de tous les éléments de $$$W$$$, $$$y$$$ est un vecteur de dimension $$$N=131$$$ des demandes de brevets en déviation à la moyenne et $$$Wy$$$ est un vecteur composé des moyennes spatialement pondérées des valeurs voisines. Définie ainsi, la statistique $$$I$$$ donne une indication du degré d’association linéaire entre un vecteur de valeurs observées $$$y$$$ et son décalage spatial $$$Wy$$$. On conclut à une autocorrélation spatiale positive lorsque $$$I$$$ est supérieur à son espérance mathématique, $$$E(I) = −1/(N−1)$$$, et à une autocorrélation spatiale négative lorsque $$$I$$$ est inférieur. L’inférence statistique est basée sur la procédure de permutation proposée par Anselin (1995a) dans laquelle une distribution de référence est générée empiriquement pour le $$$I$$$ de Moran. Les pseudos niveaux de significativité obtenus permettent alors de conclure sur le test.
Les résultats du calcul de la statistique du $$$I$$$ de Moran pour notre échantillon de données sont présentés dans le tableau 1. Ils reportent, pour chaque année et chaque matrice de poids, la valeur du $$$I$$$ de Moran, son écart-type et sa valeur standardisée. Il apparaît que toutes les statistiques sont significatives quelque soit la matrice de poids et l’année [4] (probabilité critique $$$p = 0,0001$$$). Suivant la règle de décision formulée précédemment, l’hypothèse nulle d’absence d’autocorrélation spatiale est rejetée : les demandes de brevets sont positivement et spatialement autocorrélées en 1981 et en 2001. Autrement dit, les régions déposant un nombre relativement élevé (respectivement faible) de demandes de brevets sont localisées à proximité d’autres régions déposant également un nombre élevé (respectivement faible) de demandes de brevets. Ce résultat confirme donc l’impression visuelle de concentration spatiale donnée par les cartes en annexe A.1 et A.2. Il est à noter que les valeurs standardisées du $$$I$$$ de Moran augmentent légèrement en 2001, ce qui laisse supposer une tendance persistante à la concentration géographique des régions similaires. Pour la suite de l’analyse, nous retiendrons la matrice de poids $$$D2$$$, celle pour laquelle la statistique du $$$I$$$ de Moran standardisée est maximisée [5].
Tableau 1 : Statistiques $$$I$$$ de Moran
| $$$I$$$ de Moran | Ecart-type | $$$I$$$ standardisée | ||
| 1981 | $$$D1$$$ | 0,559 | 0,046 | 12,072 |
| $$$D2$$$ | 0,503 | 0,040 | 12,724 | |
| $$$D3$$$ | 0,431 | 0,036 | 11,855 | |
| 2001 | $$$D1$$$ | 0,603 | 0,047 | 12,946 |
| $$$D2$$$ | 0,537 | 0,040 | 13,550 | |
| $$$D3$$$ | 0,465 | 0,037 | 12,742 | |
Note : L’espérance de la statistique $$$I$$$ de Moran est constante ($$$E(I)= −0,007$$$).
Ces premiers résultats semblent confirmer l’existence d’externalités de connaissance localisées dans la mesure où les performances des régions en matière d’innovation ne sont pas indépendantes de leur localisation géographique. Afin d’affiner l’analyse et de fournir une évaluation de la structure locale de l’autocorrélation, nous représentons les diagrammes de Moran en 1981 et 2001 et calculons les indicateurs locaux d’association spatiale (statistiques LISA).
1.3 Analyse de l’autocorrélation spatiale locale
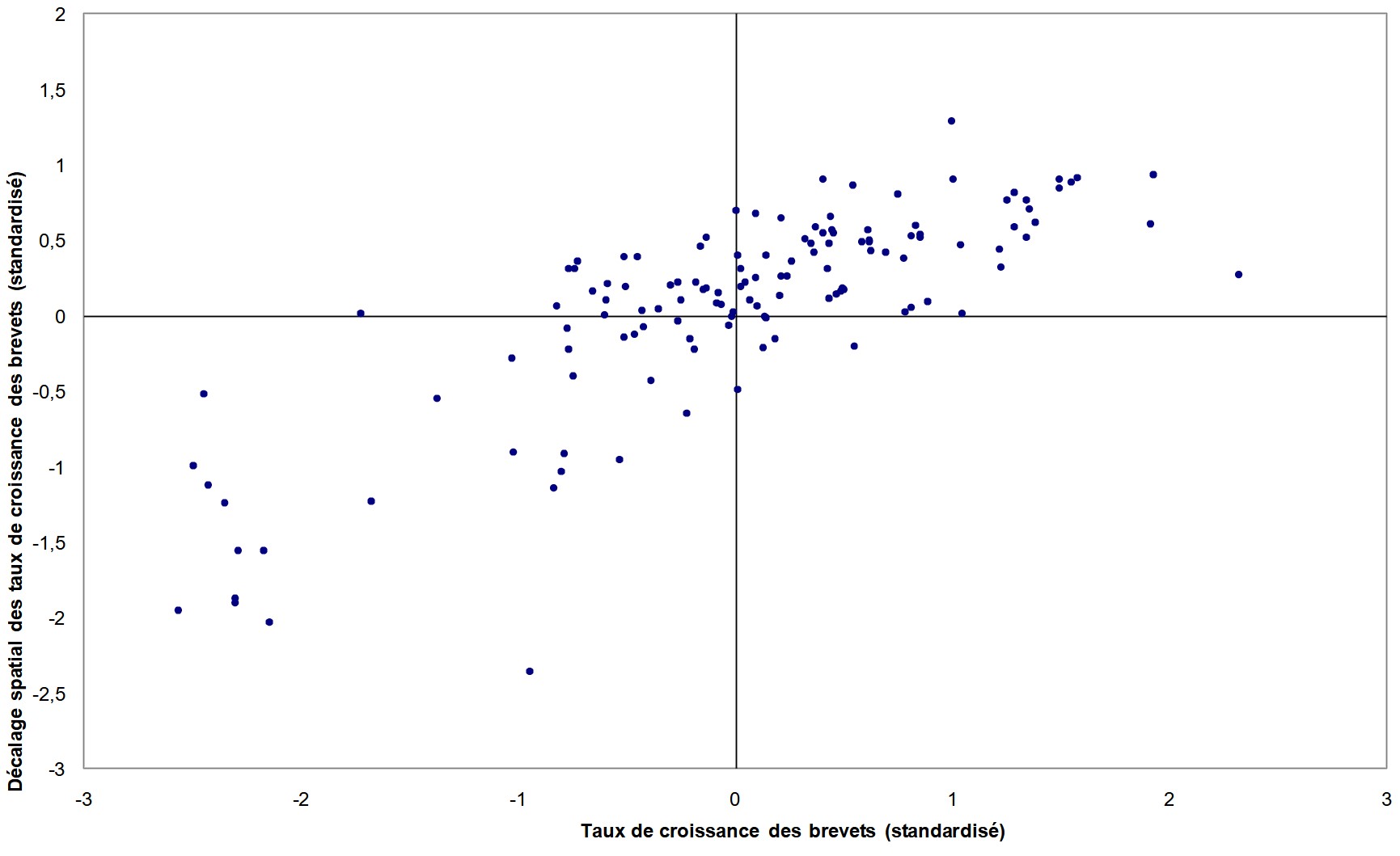
L’instabilité locale est visualisée à l’aide du diagramme de Moran (Anselin 1996). Ce diagramme représente la valeur standardisée du logarithme des demandes de brevets $$$y$$$ en abscisse et en ordonnée son décalage spatial standardisé $$$Wy$$$, c’est-à-dire la moyenne des demandes de brevets par million d’habitants des voisins. Chaque diagramme contient quatre quadrants HH, BB, BH et HB correspondants aux quatre types d’association susceptibles d’exister entre une région et ses voisines. Le quadrant HH (BB) implique qu’une région associée à une valeur élevée (faible) est entourée de régions associées à des valeurs élevées (faibles). Dans le quadrant BH (HB), une région associée à une valeur faible (élevée) est entourée de régions associées à des valeurs élevées (faibles). Les quadrants HH et BB indiquent un regroupement spatial de valeurs similaires et par conséquent une autocorrélation spatiale de type positive. A l’opposée, les quadrants BH et HB représentent une autocorrélation spatiale de type négative, c’est à dire un regroupement spatial de valeurs dissemblables. Finalement, l’autocorrélation spatiale globale peut-être visualisée sur ce graphique puisque la statistique $$$I$$$ de Moran est formellement égale à la pente de la régression linéaire de $$$Wy$$$ sur $$$y$$$.
L’analyse des diagrammes pour 1981 (figure 1) et 2001 (figure 2) confirme la présence d’une autocorrélation spatiale positive : plus de 70 % des régions appartiennent aux quadrants HH ou BB (cf. tableau 2). Quelques régions atypiques qui dévient du schéma global sont aussi mises en évidence. Ces régions, caractérisées par une association de valeurs dissemblables, appartiennent aux quadrants HB ou BH. Il est à noter que le schéma d’association BH domine le schéma HB pour les deux années ce qui indique que certaines régions éprouvent des difficultés malgré un environnement favorable. Les résultats suggèrent également l’existence d’une hétérogénéité spatiale entre les régions européennes sous la forme d’un schéma de type « centre-périphérie » dans la mesure où la majorité des régions du centre de l’Europe appartiennent au quadrant HH alors que la majorité des régions de la zone périphérique de l’Europe sont caractérisées par une association de type BB (cf. tableau de l’annexe 3).
La comparaison des diagrammes de Moran en 1981 et 2001 montre que les schémas d’association spatiale sont stables dans le temps, ce qui semble indiquer une disparité spatiale persistante entre les régions européennes. Toutefois, en dépit de cette persistance des inégalités, il est intéressant d’étudier la dynamique des associations spatiales en confrontant le diagramme de Moran des taux de croissance des demandes de brevets sur la période 1981-2001 au diagramme de Moran des demandes de brevets en 1981. En effet, l’existence d’une relation inverse entre les taux de croissance et le niveau initial des demandes de brevets impliquerait une diminution des inégalités et plaiderait en faveur d’une hypothèse de convergence des activités innovantes.
Tableau 2 : Répartition des régions dans les diagrammes de Moran
| HH | BB | HB | BH | |
| 1981 | 51,15 % | 22,14 % | 6,87 % | 19,85 % |
| 2001 | 47,33 % | 29,77 % | 7,63 % | 15,27 % |
| Tx. 81-2001 | 21,37 % | 45,80 % | 17,56 % | 15,27 % |
Après examen des diagrammes de Moran, certaines régions qui appartenaient au quadrant HH (BB) du diagramme de Moran pour les demandes de brevets en 1981 appartiennent au quadrant BB (HH) lorsque l’on considère le taux de croissance moyen sur la période 1981-2001 (cf. tableau de l’annexe A.3). Plus précisément, 58 % des régions qui se trouvaient dans un certain quadrant en 1981, se retrouvent dans un quadrant opposé pour leur taux de croissance. Toutes les régions espagnoles et la majorité des régions italiennes, très peu performantes et qui relevaient d’une association spatiale de type BB en 1981, ont un taux de croissance supérieur à la moyenne et appartiennent à une concentration de type HH pour les taux de croissance. Ceci souligne les performances en matière d’innovation de ces régions sur la période 1981-2001. Inversement, la majorité des régions très performantes et qui étaient entourées de régions aussi performantes (association de type HH), sont caractérisées par une configuration de type BB pour les taux de croissance. Ces résultats suggèrent donc l’idée d’un phénomène de rattrapage des régions les moins performantes en matière d’innovation.
Le diagramme de Moran ne donnant pas d’information sur la significativité de ces regroupements spatiaux mis en évidence, nous calculons des indicateurs particuliers : les indicateurs locaux d’association spatiale (statistiques LISA) définis par Anselin (1995a). Ces indicateurs sont aussi bien utilisés pour détecter des concentrations spatiales locales significatives, que des points atypiques (outliers) ou encore des régimes spatiaux. Selon Anselin, ces LISA doivent satisfaire deux critères. Le premier est de donner une indication sur le regroupement spatial significatif de valeurs similaires autour de chaque observation. Le second est que la somme des LISA associée à toutes les observations est proportionnelle à un indicateur global d’association spatiale. Etant donné que nous utilisons des matrices de poids standardisées, la moyenne des statistiques locales de Moran est égale à la statistique globale $$$I$$$ de Moran.
La version locale du $$$I$$$ de Moran pour chaque région $$$i$$$ et pour chaque année $$$t$$$ s’écrit :
avec $$$y_{i,t}$$$ et $$$y_{j,t}$$$ les observations de la région $$$i$$$ et $$$j$$$ à l’année $$$t$$$ (mesurées en déviation par rapport à la moyenne). La somme sur $$$j$$$ est telle que seules les régions voisines de $$$i$$$ sont incluses. Une valeur positive de $$$I_{i,t}$$$ indique une concentration spatiale de valeurs similaires (BB ou HH) alors qu’une valeur négative indique une concentration spatiale de valeurs dissemblables (BH ou HB). En raison de la présence d’autocorrélation spatiale globale, la distribution de ces statistiques est inconnue et par conséquent l’inférence statistique doit être basée sur l’approche de permutation conditionnelle avec 10 000 permutations. Les valeurs critiques obtenues sont alors des pseudos niveaux de significativité.
La significativité des statistiques LISA associées à chacune des régions est reportée dans le tableau de l’annexe A.3. Les résultats confirment la présence de concentrations spatiales significatives de valeurs élevées au centre de l’Europe qui concernent principalement des régions d’Allemagne. Il apparaît également des concentrations spatiales significatives de valeurs faibles en périphérie et qui concernent essentiellement les régions d’Espagne et d’Italie. Par conséquent, dans l’ensemble, ces statistiques confortent l’idée d’un schéma de type « centre-périphérie » mis en évidence par les diagrammes de Moran.
Bien que l’analyse exploratoire soit un outil suffisamment puissant pour expliquer les performances de chaque région en relation avec son environnement géographique, nous ne souhaitons pas fournir ici des explications plus approfondies sur les performances individuelles mais nous nous attachons plutôt à mettre en évidence des effets spatiaux (autocorrélation et hétérogénéité spatiale) et à les intégrer dans notre analyse cliométrique de la convergence.
Figure 1 : Diagramme de Moran des brevets par million d’habitants, 1981
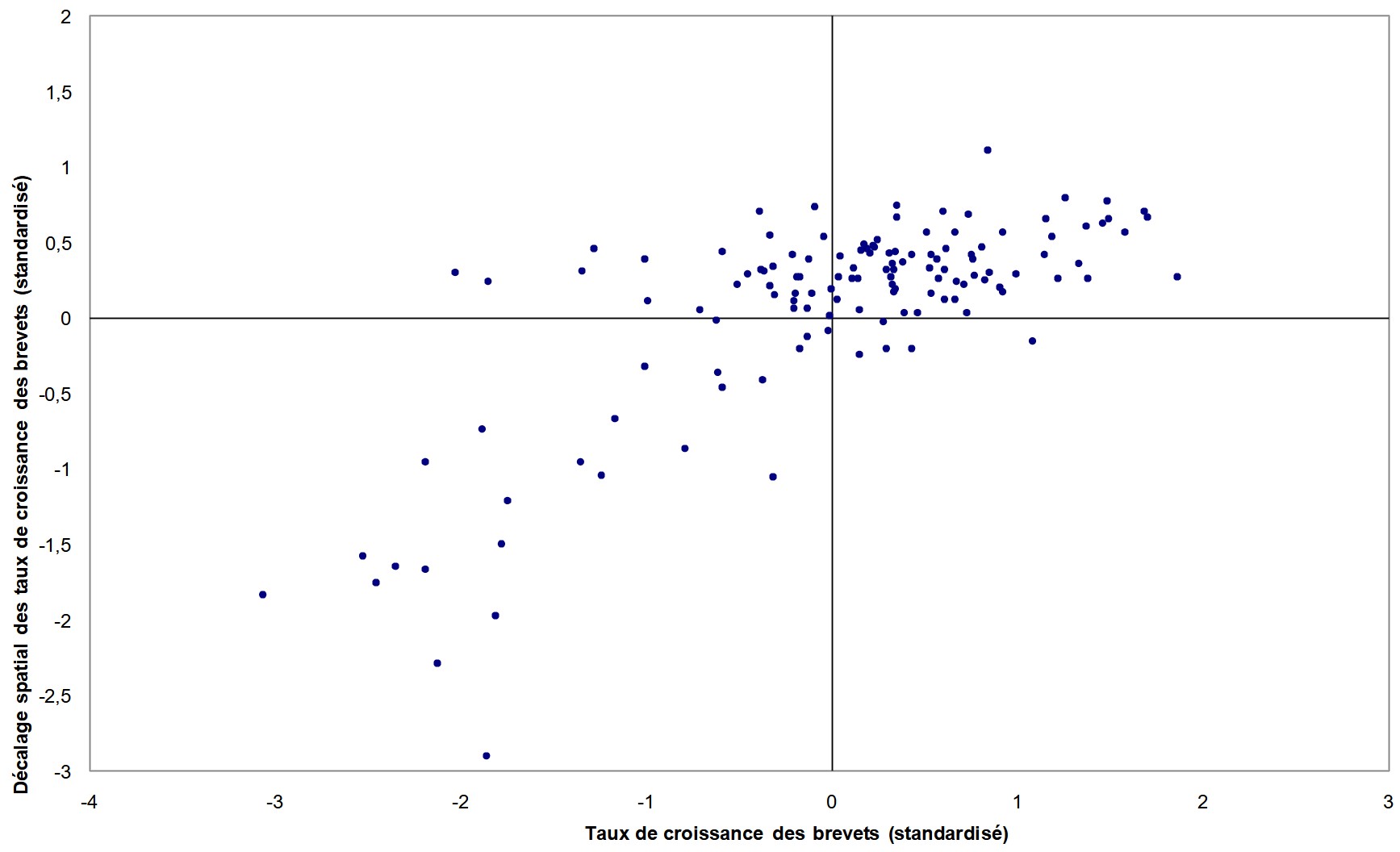
Figure 2 : Diagramme de Moran des brevets par million d’habitants, 2001
2. Convergence des activités innovantes et effets spatiaux
Nous approfondissons l’idée de convergence en testant un modèle de $$$ \beta$$$ convergence absolue semblable à celui proposé par Barro et Sala-I-Martin (1991, 1995). Comme le suggèrent Le Gallo et Dall’erba (2005), la prise en compte de l’autocorrélation spatiale dans un modèle de $$$ \beta$$$ convergence permet d’une part de capter les effets de débordement géographique entre les régions, d’autre part cela conduit à une spécification minimale de convergence conditionnelle dans la mesure où l’autocorrélation spatiale peut capter les effets des variables omises. Par ailleurs, l’omission d’éventuels effets spatiaux dans les estimations par les moindres carrés ordinaires (MCO) peut conduire à des estimateurs non convergents ni efficients.
2.1 Analyse de la $$$ \beta$$$ convergence sur la période 1981-2001
Nous estimons dans un premier temps le modèle simple de $$$ \beta$$$ convergence absolue suivant :
où $$$gpat$$$ est le taux de croissance annuel moyen des demandes de brevets par habitant sur la période 1981-2001, $$$pat81$$$ est le logarithme des demandes de brevets déposées en 1981 et $$$S$$$ est un vecteur unitaire. Le processus de convergence est caractérisé par une vitesse de convergence, $$$\nu =-\ln(1+\hat \beta T) / T$$$ et une demi-vie, $$$\tau =-\ln(2) / \ln (1+ \hat \beta )$$$, correspondante au temps nécessaire à l’économie pour atteindre la moitié de la distance qui la sépare de son état stationnaire.
Les résultats de l’estimation de ce premier modèle par la méthode des moindres carrés ordinaires (MCO) apparaissent dans les deux premières colonnes du tableau 3. La valeur du coefficient associé aux brevets par habitant est négative et significative, ce qui nous conduit à accepter l’hypothèse de $$$ \beta$$$ convergence absolue entre les régions européennes. Sur la période 1981-2001, les régions qui déposent peu de demandes de brevets en 1981 ont un taux de croissance plus élevé que les régions les plus performantes, ce qui favorise donc le rattrapage des régions les moins performantes. La vitesse de convergence est alors estimée à 2,65 % par an et la demi-vie est de 34 ans. L’analyse exploratoire ayant révélé la présence d’effets spatiaux dans la distribution régionale des demandes de brevets, une série de test doit être réalisée sur ce modèle afin de détecter et d’identifier la forme la plus appropriée de ces effets spatiaux. En effet, si des effets spatiaux sont mis en évidence dans le modèle, ils seront par la suite inclus dans une nouvelle spécification cliométrique.
Le test de Moran (1948) adapté aux résidus d’une régression par Cliff et Ord (1981) donne une valeur significative indiquant qu’il existe une dépendance spatiale positive entre les résidus de la régression. Il convient alors de discriminer entre les deux formes d’autocorrélation spatiale possibles : l’autocorrélation spatiale des erreurs ou une variable endogène décalée [6]. Anselin et Florax (1995) proposent des tests basés sur le multiplicateur de Lagrange : les statistiques LM (Error) et LM (Lag) qui permettent de discriminer entre ces deux formes. Le test LM (Error) possède l’hypothèse nulle d’une autocorrélation spatiale des erreurs tandis que le test LM (Lag) possède l’hypothèse nulle d’absence d’une variable autorégressive supplémentaire. Suivant la règle de décision suggérée par les deux auteurs, nous constatons que seule la statistique LM (Error) est significative [7]. Le modèle 1 apparaît par conséquent mal spécifié en raison de l’omission de l’autocorrélation spatiale des termes d’erreur. Un second modèle incorporant explicitement cette dépendance [8] est alors estimé :
où $$$\lambda$$$ est un paramètre représentant l’intensité de l’autocorrélation spatiale entre les résidus de la régression. En présence d’autocorrélation spatiale, l’estimation par les MCO ne produisant plus des estimateurs efficients, il est nécessaire de procéder à une estimation par la méthode du maximum de vraisemblance (MV). Les résultats de cette nouvelle estimation sont reportés dans le tableau 3. Ils montrent que l’hypothèse de convergence est également acceptée et que le coefficient $$$ \beta$$$ associé au niveau initial des demandes de brevets est supérieur au coefficient $$$ \beta$$$ estimé par la méthode des MCO. La vitesse de convergence augmente alors et atteint 3,87 % pour une demi-vie réduite à 26 ans. Il apparaît aussi une forte autocorrélation spatiale positive et significative des erreurs ( $$$ \hat \lambda = 0,80$$$).
Tableau 3 : Estimations et tests des modèles 1 et 2
| MODELE 1 | MODELE 2 | |||
| MCO | Coefficient (p-critique) | MV | Coefficient (p-critique) | |
| $$\hat \alpha $$ | 0,141(0,00) | $$\hat \alpha $$ | 0,154(0,00) | |
| $$ \hat \beta$$ | −0,020(0,00) | $$ \hat \beta$$ | −0,026(0,00) | |
| Vitesse de convergence | 2,65 % | Vitesse de convergence | 3,87 % | |
| Demi-vie | 34 | Demi-vie | 26 | |
| $$$I$$$ de Moran | 6,001(0,00) | $$\hat \lambda$$ | 0,801(0,00) | |
| LM (Error) | 29,043(0,00) | Spatial Breusch-Pagan | 11,533(0,00) | |
| LM (Lag) | 1,512(0,21) | |||
| Koenker-Bassett | 7,363(0,00) | LM* (Lag) | 0,500(0,47) | |
| AIC | −567,39 | AIC | −599,21 | |
| SC | −561,64 | SC | −593,46 | |
Le test complémentaire LM*(lag) indique qu’une variable endogène supplémentaire n’est pas nécessaire. Par ailleurs, sur la base des critères d’information d’Akaike (1974) et de Schwarz (1978), le second modèle est préférable au premier.
Ces résultats confirment l’intuition de convergence émise précédemment. L’estimation d’un modèle avec autocorrélation des erreurs est la spécification la plus appropriée. De plus, elle est assortie d’une vitesse de convergence plus élevée que celle du modèle initial. Ainsi, les débordements de connaissance, liés à la proximité spatiale, semblent avoir un impact positif sur le processus de convergence des régions européennes. Toutefois, d’après le test d’hétéroscédasticité de Breuch-Pagan (1979) spatialement ajusté, il subsiste une certaine hétérogénéité spatiale. La présence d’hétérogénéité spatiale se manifeste dans la régression cliométrique par un problème d’hétéroscédasticité lié par exemple à l’utilisation d’unités spatiales hétérogènes et/ou par une instabilité des paramètres qui varient selon la localisation (Le Gallo 2004). Dans ce dernier cas, il est possible que les coefficients de l’équation de convergence ne soient pas stables dans l’espace. Les conclusions de l’analyse exploratoire menée dans la section précédente, mettant en évidence un clivage de type centre-périphérie, confortent l’idée d’une hétérogénéité sous la forme de régimes spatiaux différents. En effet, il semble pertinent de supposer que le processus de convergence n’est peut-être pas identique pour toutes les régions européennes mais qu’au contraire, il n’apparaît que pour des groupes de régions partageant des conditions initiales similaires. Nous testons donc cette hypothèse à partir de la méthode des données réordonnées proposée par Jean-pierre (1997), qui permet d’identifier ces clubs ou groupes de régions ayant chacun leur propre régime de convergence.
2.2 Des régimes de convergence différents
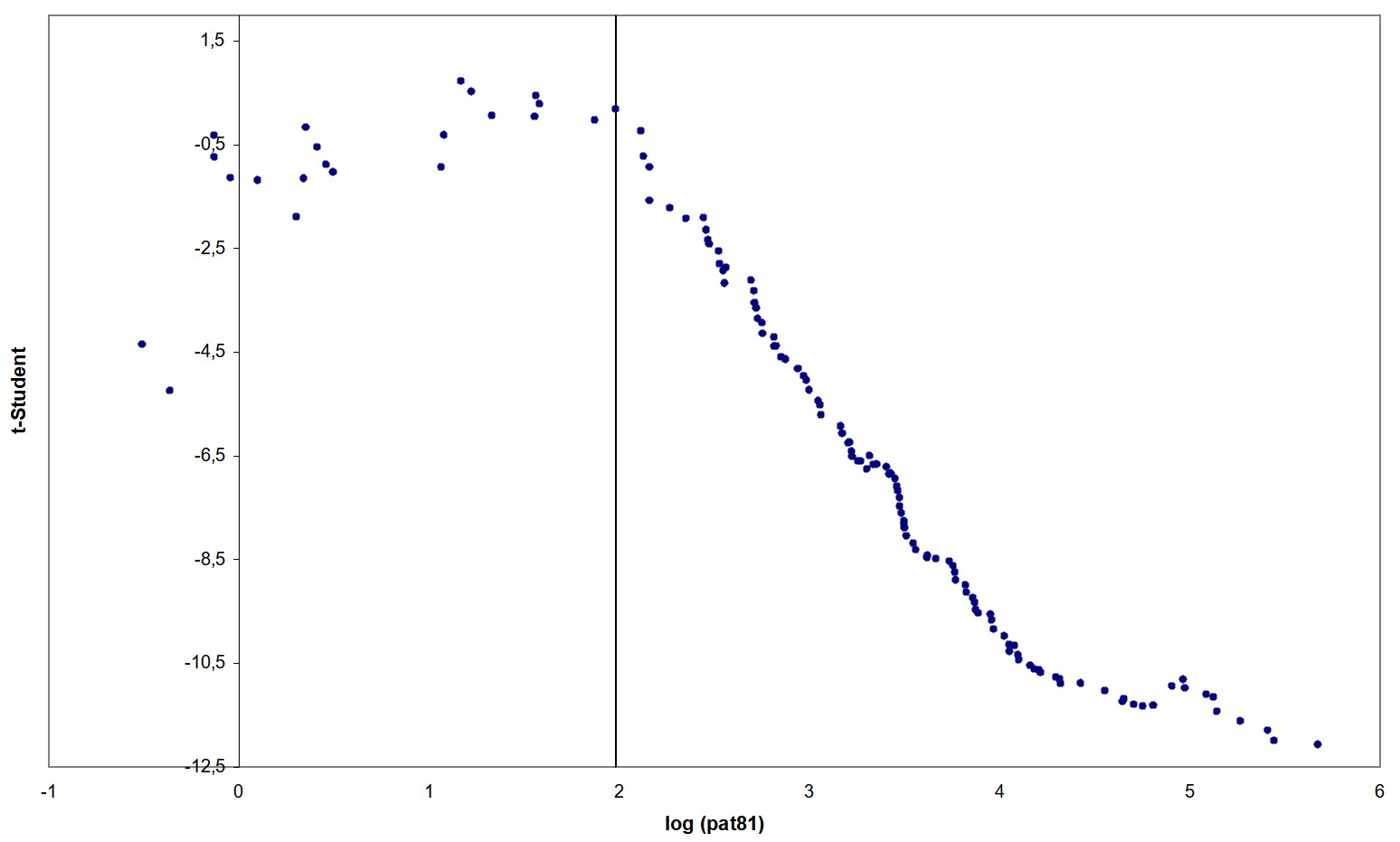
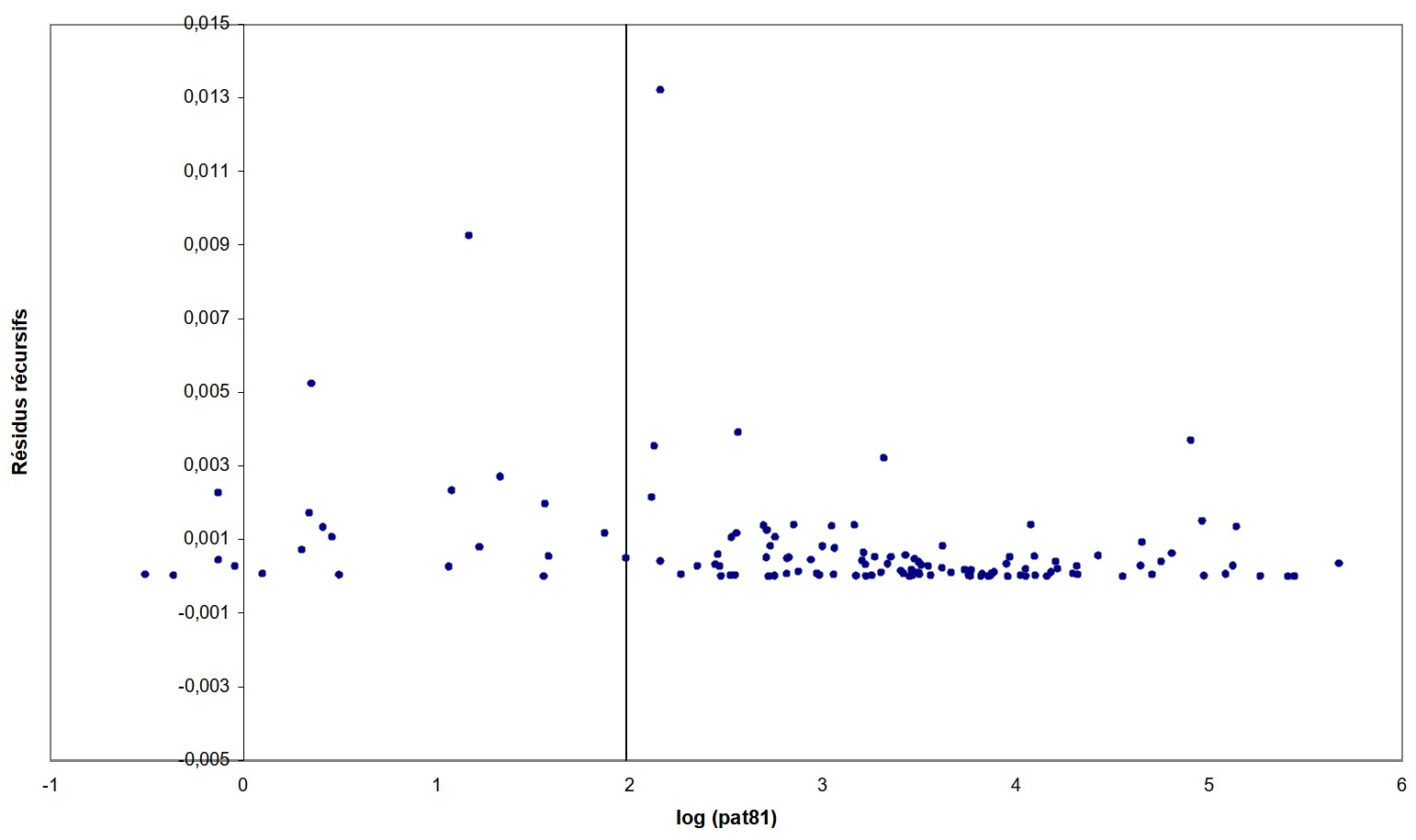
La méthode des données réordonnées de Jean-Pierre (1997) consiste à déterminer de manière endogène des clubs de convergence, c’est-à-dire des groupes d’économies ayant des conditions initiales similaires et convergeant vers un même équilibre stable à long terme. Cette méthode est basée sur les travaux de Tong et Lim (1980) et Tong (1983), repris par la suite par Tsay en 1989. Elle consiste à effectuer des régressions sur des données préalablement réordonnées afin d’identifier des seuils de rupture qui laissent supposer l’existence de régimes de convergence différenciés. Plusieurs étapes sont nécessaires à l’identification de ces régimes. Dans un premier temps, les demandes de brevets par million d’habitants en 1981 sont reclassées par ordre croissant. Ensuite, la stabilité des coefficients de l’équation de convergence du modèle 1 est testée à partir d’un test de Fischer [9]. Dans le cas où l’hypothèse nulle de stabilité est rejetée, le ou les seuils séparant les différents groupes de régions doivent être localisés. Pour cela, une première régression est effectuée sur les $$$n$$$ premières observations [10] permettant de déduire le $$$t$$$ de Student du coefficient $$$ \beta$$$. On procède ensuite à des estimations récursives jusqu’à ce que l’ensemble de l’échantillon ait été utilisé. La dernière étape est la localisation des seuils à partir d’une représentation graphique des $$$t$$$ de Student récursifs en fonction de la variable seuil choisie, c’est-à-dire du niveau initial des demandes de brevets en 1981. L’interprétation graphique est la suivante : tout changement de direction dans la courbe des $$$t$$$ de Student peut marquer la présence d’un nouveau régime. Cette analyse graphique est parfois complétée par la représentation graphique d’autres indicateurs, tels que les résidus récursifs standardisés. Dans ce cas, une analyse en termes de changement de forme du nuage de points est plus appropriée.
L’application de cette méthodologie à notre équation de convergence absolue du modèle 1 conduit au rejet de l’hypothèse de stabilité des coefficients de l’équation. La figure de l’annexe A.4 représentant les $$$t$$$ de Student récursifs fait apparaître un changement de régime pour un logarithme des demandes de brevets ($$$pat81$$$) au alentour de 1.98, soit environ 7 brevets par million d’habitants. Jusqu’à ce seuil, la série $$$pat81$$$ croît légèrement et au-delà, elle change brutalement de tendance et décroît de manière exponentielle. Le graphique des résidus récursifs en annexe A.5 confirme cette hypothèse de changement de régime pour le même seuil. Ainsi, deux groupes de régions ayant des régimes distincts sont mis en évidence.
Le groupe 1 est composé de 24 régions appartenant à une zone « périphérique » de l’Europe : Espagne, Italie du sud (Provincia Autonoma Trento, Umbria, Marche, Abruzzo, Molise, Campania, Puglia, Basilicata, Calabria, Sicilia, Sardegna), Irlande, Allemagne de l’est (Oberfranken, Mittelfranken, Braunschweig, Thüringen), Autriche (Kärnten), Royaume-Uni (South West).
Le groupe 2 est composé de 107 régions appartenant à la zone « centre » de l’Europe [11] : Autriche (sauf Kärnten), Belgique, Allemagne (sauf Oberfranken, Mittelfranken, Braunschweig, Thüringen), France, Italie du nord (Piemonte, Valle d’Aosta, Liguria, Lombardia, Provincia Autonoma Bolzano-Bozen, Veneto, Friuli-Venezia Giulia, Emilia-Romagna, Toscana, Lazio), Luxembourg, Pays-Bas, Suède, Royaume-Uni (sauf South West).
L’hétérogénéité spatiale causée par l’instabilité structurelle est alors modélisée par une spécification intégrant ces deux régimes spatiaux. Nous procédons alors à deux nouvelles estimations (modèles 3 et 4). A la différence du modèle 3, le modèle 4 incorpore de l’autocorrélation spatiale.
où $$$G_1$$$ et $$$G_2$$$ représentent des variables muettes correspondantes aux deux groupes identifiés. L’avantage de cette nouvelle spécification est double : d’une part, elle autorise d’éventuels régimes de convergence différents et d’autre part, la même matrice d’interaction spatiale $$$W$$$ est utilisée, ce qui permet aux régions des deux groupes d’interagir entres elles. En revanche, cela conduit à considérer que l’autocorrélation spatiale est identique au sein des régions du centre et de la périphérie.
D’après les résultats reportés dans le tableau 4, il apparaît tout d’abord que le modèle 3 est mal spécifié en raison de la présence d’une autocorrélation spatiale des erreurs. En effet, la statistique $$$I$$$ de Moran et le test LM (Error) sont tous deux significatifs. Le modèle 4 intégrant cette autocorrélation est par conséquent le plus approprié. Par ailleurs, les résultats montrent une convergence significative seulement pour les régions appartenant au centre de l’Europe car seul le coefficient $$$ \beta_2$$$ est négatif et significatif. La vitesse de convergence est de 2,86 % et la demi-vie de 32 ans. Finalement, le test de Breuch-Pagan conduit à accepter l’hypothèse nulle d’homoscédasticité (probabilité critique $$$p = 0,24$$$). Il semble donc que l’instabilité spatiale ait été totalement prise en compte par la spécification du modèle 4. De plus, ce dernier modèle est préférable aux modèles précédents du point de vue des critères d’information d’Akaike et de Schwarz.
Tableau 4 : Estimations et tests des modèles 3 et 4
| MODELE 3 | MODELE 4 | |||
| MCO | Coefficient (p-critique) | MV | Coefficient (p-critique) | |
| $$$\hat \alpha_1$$$ | 0,141(0,00) | $$$\hat \alpha_1$$$ | 0,156(0,00) | |
| $$$\hat \beta_1$$$ | 0,001(0,77) | $$$\hat \beta_1$$$ | −0,008(0,15) | |
| $$$\hat \alpha_2$$$ | 0,117(0,00) | $$$\hat \alpha_2$$$ | 0,132(0,00) | |
| $$$\hat \beta_2$$$ | −0,014(0,00) | $$$\hat \beta_2$$$ | −0,021(0,00) | |
| Vitesse de convergence (G2) | 1,68 % | Vitesse de convergence (G2) | 2,86 % | |
| Demi-vie (G2) | 49 | Demi-vie (G2) | 32 | |
| $$$I$$$ de Moran | 6,537(0,00) | $$$ \hat \lambda$$$ | 0,823(0,00) | |
| LM (Error) | 32,604(0,00) | Spatial Breusch-Pagan | 5,469(0,24) | |
| LM (Lag) | 0,817(0,36) | |||
| Koenker-Bassett | 10,274(0,03) | LM (Lag) | 2,055(0,15) | |
| AIC | −585,96 | AIC | −621,39 | |
| SC | −574,46 | SC | −609,89 | |
Au vu de l’ensemble des résultats, il apparaît clairement que le processus de convergence régional global masque des disparités entre les régions européennes. Un seul processus de convergence semble exister et ne concerne que les régions localisées au centre de l’Europe. En dépit de la présence d’effets spatiaux, le premier groupe composé des régions ayant une activité de dépôts de brevets quasi nulle n’amorce pas de processus de convergence. Au contraire, ces régions semblent appartenir à une sorte de trappe de sous-développement technologique dans le sens où elles ne disposeraient pas des capacités d’absorption nécessaires pour capter les spillovers technologiques et enclencher ainsi un processus de rattrapage. Il apparaît nécessaire que ces régions défavorisées orientent leurs efforts de R&D vers l’acquisition des savoirs ou compétences adéquats qui leur permettront de tirer profit des connaissances développées à l’extérieur (Cohen et Levinthal 1989).
Conclusion
Dans cet article, nous avons analysé la double influence des effets de débordement de connaissance liés à la proximité géographique, d’une part sur les performances régionales en matière d’innovation, et d’autre part sur le processus de convergence des activités innovantes. La mobilisation des techniques de l’économétrie spatiale au profit de l’analyse cliométrique a révélé la présence d’effets spatiaux impliquant que l’activité de dépôt de brevets d’une région est corrélée positivement au dynamisme des régions voisines. Outre l’importance de considérer la localisation géographique et l’environnement dans les analyses sur les disparités régionales, notre approche suggère la nécessité de prendre en compte les interactions spatiales lors de la mise en œuvre des actions régionales pour la recherche et la technologie. En effet, si des débordements de connaissance interrégionaux existent et conditionnent les performances d’une région à celles de son entourage, il n’en demeure pas moins que la diffusion de ces effets n’est ni immédiate ni dénuée de coûts. L’analyse de la convergence des activités innovantes au niveau régional a mis en évidence un schéma spatial de type centre-périphérie caractérisé par un seul processus de convergence en faveur des régions du centre de l’Europe. Alors que ces régions du centre bénéficient des effets positifs des externalités de connaissance sur leur vitesse de convergence, les régions de la périphérie les moins performantes accusent un tel retard technologique qu’il leur est difficile d’amorcer un processus de convergence. Ces régions, déjà pénalisées du fait de leur éloignement, semblent ne pas disposer des capacités d’absorption indispensables pour tirer profit des externalités. Nos résultats, en guise de leçons de l’histoire, confirment dès lors l’importance de mettre en place des politiques régionales adaptées au contexte social et économique des régions concernées. Les régions industrialisées, proches de la frontière technologique, bénéficiant d’un environnement socioéconomique favorable à l’innovation doivent continuer à développer leur capacité créatrice afin de maintenir leur compétitivité. Les régions de la périphérie, dont l’activité de dépôt de brevets est quasi inexistante, sont pour la plupart caractérisées par une faible activité de R&D, un système d’innovation souvent partiel et par une économie à dominance agricole. Une capacité d’absorption et des capacités de transfert conséquentes étant indispensables à l’efficience de la capacité créatrice (Bikar et al. 2006), toute action visant à réduire les disparités devrait par conséquent se concentrer sur le développement de la capacité d’absorption des régions, via notamment la formation d’une main d’œuvre qualifiée répondant aux besoins spécifiques de ces régions et des régions voisines.
Claude Diebolt
Directeur de Recherche au CNRS à l’Université de Strasbourg
cdiebolt unistra.fr
Cet article a été préparé pour un numéro spécial du Bulletin de l’OPEE (Observatoire des Politiques Economiques en Europe), publié dans le cadre du 50ème anniversaire du BETA (Bureau d’Économie Théorique et Appliquée). Je suis très reconnaissant aux deux rapporteurs et à l’éditeur du Bulletin de l’OPEE pour leurs critiques, remarques et suggestions. Les éventuelles erreurs et insuffisances demeurent bien sûr miennes.
Références bibliographiques
Acs Z., Anselin L., Varga V. (2002), « Patents and Innovation Counts as Measures of Regional Production of New Knowledge », Research Policy 31, 1069−1085.
Akaike H. (1974), « A New Look at the Statistical Model Identification », IEEE Transactions on Automatic Control, AC-19, 716−723.
Anselin L. (1988), Spatial Econometrics : Methods and Models, Kluwer Academic Publishers, Boston, Dordrecht.
Anselin, L. (1995a), « Local Indicators of Spatial Association-LISA », Geographical Analysis 27(2), 93−115.
Anselin L. (1995b), SpaceStat, A Software Program for the Analysis of Spatial Data, Version 1.80, Regional Research Institute, West Virginia University, Morgantown, WV.
Anselin L. (1996), « The Moran Scatterplot as an ESDA Tool to Assess Local Instability in Spatial Association », in : Fischer M., Scholten M., Unwin D. (eds.), Spatial Analytical Perspectives on GIS, London, Taylor & Francis.
Anselin L., Bera A. (1998), « Spatial Dependance in Linear Regression Models with an Introduction to Spatial Econometrics ». In : Ullah A. and Giles DEA (Eds.), Handbook of Applied Economic Statistics, Berlin, Springer.
Anselin L., Florax, R. (1995), « Small Sample Properties of Tests for Spatial Dependance in Regression Models », in : Anselin L., Florax, R. (eds), New Directions in Spatial Econometrics, Berlin, Springer-Verglag.
Basberg B. (1987), « Patents and the Measurement of Technological Change : A Survey of the Literature », Research Policy 16, 131−141.
Barro R., Sala-I-Martin X. (1991), « Convergence Across States and Regions », Brookings Papers on Economic Activity, n° 1, 107−182.
Barro R., Sala-I-Martin X. (1995), Economic Growth, New York, McGraw Hill.
Breusch T., Pagan, A. (1979), « A Simple Test for Heteroskedasticity and Random Coefficient Variation », Econometrica 47(5), 1287−1294.
Bikar V., Capron H., Cincera M. (2006), « Analyse intégrée des systèmes d’innovation nationaux Européens : une approche institutionnelle », in : Capron H., eds., Politique régionale européenne : Convergence et dynamique d’innovation, De Boeck, Bruxelles, 165−187.
Cohen W., Levinthal D. (1989), « Innovation and Learning : The Two Faces of R & D », Economic Journal 99(397), 569−596.
Cliff A., Ord J. (1981), Spatial Processes : Models and Applications, London, Pion.
Diebolt C. (2016), « Cliometrica after 10 Years : Definition and Principles of Cliometric Research », Cliometrica 10(1), 1−4.
Diebolt C., Haupert M. (2019), Handbook of Cliometrics, 2nd edition, 2 vols, Berlin, Springer.
Diebolt C., Hippe R. (2022), Human Capital and Regional Development in Europe. A Long-Run Comparative View, Berlin, Springer.
Diebolt C., Pellier K. (2020), « Patents in the Long Run : Theory, History, and Statistics », History & Mathematics 8, 80−119.
Griliches Z. (1990), « Patent Statistics as Economic Indicators : A Survey », Journal of Economic Literature 28(4), 1661−1707.
Jean-Pierre P. (1997), « Sélection et tests de seuils de convergence », Revue économique, vol. 48, n° 3, 429−440.
Le Gallo J. (2002), « Econométie spatiale : l’autocorrélation spatiale dans les modèles de régression linéaire », Economie et Prévision 155(4), 139−158.
Le Gallo J. (2004), « Hétérogénéité spatiale, principes et méthodes », Economie et Prévision 162(1), 151−172.
Le Gallo J., Dall’erba S. (2005), « Dynamique du processus de convergence régional en Europe », Région et Développement, n° 21, 119−138.
Moran P.A.P. (1948), « The Interpretation of Statistical Maps », Journal of the Royal Statistical Society, Series B, 10(2), 243−251.
Schwarz G. (1978), « Estimating the Dimension of a model », Annals of Statistics 6(2), 461−464.
Tong H., Lim K.S. (1980), « Threshold Autoregression Cycles and Cyclical Data », Journal of the Statistical Society 42(3), 245-292.
Tong H. (1983), « Threshold Models in Non Linear Time Series Analysis », Lecture Notes in Statistics, n° 21, New-York, Springer Verglag.
Tsay R.S. (1989), « Testing and Modelling Threshold Autoregressive Process », Journal of American Statistical Association 84(405), 231−240.
Annexes
A.1 Demandes de brevets relatives à la moyenne européenne en 1981
A.2 Demandes de brevets relatives à la moyenne européennes en 2001
A.3 Autocorrélation spatiale locale
| Groupe | Code Nuts | Région | 1981 | 2001 | 81-01 |
| 2 | at11 | Burgenland | BH | BH | HB |
| 2 | at12 | Niederösterreich | HH | HH | BB |
| 2 | at13 | Wien | HH | HH | BB |
| 1 | at21 | Kärnten | BH | HH | HB* |
| 2 | at22 | Steiermark | HB | HH | BH |
| 2 | at31 | Oberösterreich | HH | HH | BH |
| 2 | at32 | Salzburg | HH | HH | BH |
| 2 | at33 | Tirol | HH | HH | BH |
| 2 | at34 | Vorarlberg | HH | HH* | HB |
| 2 | be10 | Région de Bruxelles-Capitale | HH | HH | BH |
| 2 | be21 | Prov. Antwerpen | HH | HH | BB |
| 2 | be22 | Prov. Limburg (B) | BH | BH | HB |
| 2 | be23 | Prov. Oost-Vlaanderen | BH | HH | HB |
| 2 | be24 | Prov. Vlaams Brabant | HH | HH | HB |
| 2 | be25 | Prov. West-Vlaanderen | BH | BB | HB |
| 2 | be31 | Prov. Brabant Wallon | HH | HH | BB |
| 2 | be32 | Prov. Hainaut | BH | BH | BB |
| 2 | be33 | Prov. Liège | HH | HH | BB |
| 2 | be34 | Prov. Luxembourg (B) | HH | BH | BB |
| 2 | be35 | Prov. Namur | BH | BH | BB |
| 2 | de11 | Stuttgart | HH* | HH* | BH |
| 2 | de12 | Karlsruhe | HH* | HH* | BB |
| 2 | de13 | Freiburg | HH* | HH* | BB |
| 2 | de14 | Tübingen | HH* | HH* | BB |
| 2 | de21 | Oberbayern | HH* | HH* | BH |
| 2 | de22 | Niederbayern | HH | HH* | HH |
| 2 | de23 | Oberpfalz | BH | HH* | HH* |
| 1 | de24 | Oberfranken | BB | HH* | HH* |
| 1 | de25 | Mittelfranken | BH* | HH* | HH* |
| 2 | de26 | Unterfranken | HH | HH* | HH |
| 2 | de27 | Schwaben | HH* | HH* | BH |
| 2 | de50 | Bremen | HH | HH | BH |
| 2 | de60 | Hamburg | HB | HH | BH |
| 2 | de71 | Darmstadt | HH* | HH* | BB |
| 2 | de72 | Gießen | HH | HH* | BB |
| 2 | de73 | Kassel | HH | HH | BH |
| 1 | de91 | Braunschweig | BH | HH | HH |
| 2 | de92 | Hannover | HH | HH* | BH |
| 2 | de93 | Lüneburg | BH | HH | HB |
| 2 | de94 | Weser-Ems | BH | HH | HB |
| 2 | dea1 | Düsseldorf | HH* | HH* | BB |
| 2 | dea2 | Köln | HH* | HH* | BB* |
| 2 | dea3 | Münster | HH | HH | BB |
| 2 | dea4 | Detmold | HH | HH | HB |
| 2 | dea5 | Arnsberg | HH | HH* | BB |
| 2 | deb1 | Koblenz | HH* | HH | BB* |
| 2 | deb2 | Trier | HH | BH | BB* |
| 2 | deb3 | Rheinhessen-Pfalz | HH* | HH* | BB* |
| 2 | dec0 | Saarland | HH | HH | BB |
| 2 | def0 | Schleswig-Holstein | BH | HH | HB |
| 1 | deg0 | Thüringen | BH* | BH | HH* |
| 2 | dk00 | Danemark | HH | HH | HB |
| 1 | es1 | Noroeste | BB* | BB* | HH* |
| 1 | es2 | Noreste | BB* | BB* | HH* |
| 1 | es3 | Comunidad de Madrid | BB* | BB* | HH* |
| 1 | es4 | Centro | BB* | BB* | HH* |
| 1 | es5 | Este | BB* | BB* | HH* |
| 1 | es6 | Sur | BB* | BB* | HH* |
| 2 | fr10 | Île de France | HH | HB | BB* |
| 2 | fr21 | Champagne-Ardenne | HH | BH | BB* |
| 2 | fr22 | Picardie | HH | BH | BB* |
| 2 | fr23 | Haute-Normandie | HH | BB | BB |
| 2 | fr24 | Centre | HH | BH | BB |
| 2 | fr25 | Basse-Normandie | BH | BB | HB |
| 2 | fr26 | Bourgogne | HH | BH | BB* |
| 2 | fr30 | Nord-Pas-de-Calais | BH | BB | BB |
| 2 | fr41 | Lorraine | BH | BH | BB |
| 2 | fr42 | Alsace | HH* | HH | BB |
| 2 | fr43 | Franche-Comté | HH* | HH | BB* |
| 2 | fr51 | Pays de la Loire | BH | BB | BB |
| 2 | fr52 | Bretagne | BB | HB | HB |
| 2 | fr53 | Poitou-Charentes | BB | BB | BB |
| 2 | fr61 | Aquitaine | BB | BB | BB |
| 2 | fr62 | Midi-Pyrénées | HB | HB | BB |
| 2 | fr63 | Limousin | HH | BB | BB |
| 2 | fr71 | Rhône-Alpes | HH | HB | BB |
| 2 | fr72 | Auvergne | HH | HB | HB |
| 2 | fr81 | Languedoc-Roussillon | BB | BB | BB |
| 2 | fr82 | Provence-Alpes-Côte d’Azur | HH | BB | BB |
| 2 | fr83 | Corse | BB | BB* | BH |
| 1 | ie0 | Irlande | BB | BB | HB |
| 2 | itc1 | Piemonte | HB | HB | BH |
| 2 | itc2 | Valle d’Aosta | BH | BH | HB |
| 2 | itc3 | Liguria | BB | BB | HH |
| 2 | itc4 | Lombardia | HB | HH | HH |
| 2 | itd1 | Provincia Autonoma Bolzano-Bozen | BH | BH | BH |
| 1 | itd2 | Provincia Autonoma Trento | BH | BH | HH |
| 2 | itd3 | Veneto | BB | HB | HH |
| 2 | itd4 | Friuli-Venezia Giulia | HB | BH | BH |
| 2 | itd5 | Emilia-Romagna | HB | HB | HH |
| 2 | ite1 | Toscana | BB | BB | HH |
| 1 | ite2 | Umbria | BB | BB | HH |
| 1 | ite3 | Marche | BB | BB | HH |
| 2 | ite4 | Lazio | BB | BB* | BH |
| 1 | itf1 | Abruzzo | BB* | BB* | HH |
| 1 | itf2 | Molise | BB* | BB* | HH |
| 1 | itf3 | Campania | BB* | BB* | HH |
| 1 | itf4 | Puglia | BB* | BB* | HH |
| 1 | itf5 | Basilicata | BB* | BB* | HH |
| 1 | itf6 | Calabria | BB* | BB* | HH |
| 1 | itg1 | Sicilia | BB* | BB* | HH |
| 1 | itg2 | Sardegna | BB* | BB* | HB |
| 2 | lu00 | Luxembourg | HH | HH | BB* |
| 2 | nl11 | Groningen | BH | BB | HB |
| 2 | nl12 | Friesland | BH | BH | BB |
| 2 | nl13 | Drenthe | HB | BB | BB |
| 2 | nl21 | Overijssel | HH | HH | BB |
| 2 | nl22 | Gelderland | HH | HH | BB |
| 2 | nl23 | Flevoland | BH | BH | HB |
| 2 | nl31 | Utrecht | HH | HH | BB |
| 2 | nl32 | Noord-Holland | HH | HH | BB |
| 2 | nl33 | Zuid-Holland | HH | HH | BB |
| 2 | nl34 | Zeeland | HH | BH | BB |
| 2 | nl41 | Noord-Brabant | HH* | HH* | HB |
| 2 | nl42 | Limburg | HH | HH | BB |
| 2 | se01 | Stockholm | HH | HH | BB |
| 2 | se02 | Östra Mellansverige | HH | HH | BB |
| 2 | se04 | Sydsverige | HH | HH* | BH |
| 2 | se06 | Norra Mellansverige | HH | HH | BB |
| 2 | se07 | Mellersta Norrland | BH | HH | HB |
| 2 | se08 | Övre Norrland | HH | HH | BH |
| 2 | ukc | North East | HH | BB | BB |
| 2 | ukd | North West | HH | BB | BB |
| 2 | uke | Yorkshire and The Humber | HH | BB | BB* |
| 2 | ukf | East Midlands | HH | BH | BB |
| 2 | ukg | West Midlands | HB | HB | BB |
| 2 | ukh | Eastern | HH | HH | BB |
| 2 | ukj | South East | HH | HB | BB |
| 1 | ukk | South West | BB | BB | BB |
| 2 | ukl | Wales | BH* | BB | HB* |
| 2 | ukn | Northern Ireland | BB | BB | BH |
Note : * indique que la statistique LISA correspondante est significative (seuil de 5 %).
A.4 $$$t$$$ de Student récursifs
A.5 Résidus récursifs standardisés
[1] Le découpage territorial établi par Eurostat est la Nomenclature des unités territoriales statistiques (NUTS). Celle-ci fournit une ventilation unique et uniforme des unités territoriales pour la production de statistiques régionales de l’Union Européenne. La NUTS est une classification hiérarchique à cinq niveaux comprenant trois niveaux régionaux (NUTS 1 à 3) et deux niveaux locaux (NUTS 4 et 5). Ainsi, selon cette classification, chaque état membre est subdivisé en un nombre entier de régions de niveau 1, dont chacune est subdivisée en un nombre entier de régions de niveau 2, et ainsi de suite.
[2] La pertinence des statistiques de brevets comme indicateur de la production d’innovations au niveau régional est démontré par Acs, Anselin et Varga (2002). Griliches (1990) et Basberg (1987) discutent également des avantages et des inconvénients d’utiliser les brevets comme indicateur de l’activité d’innovation.
[3] Cette augmentation s’explique en partie par une modification du choix de la voie de dépôt du brevet, la voie européenne étant dorénavant privilégiée à la voie nationale.
[4] Tous les calculs ont été effectués avec le logiciel SpaceStat 1.91 (Anselin 1995b).
[5] La robustesse des résultats est testée avec les autres matrices de poids.
[6] Voir Le Gallo (2002) pour une présentation des procédures d’estimation en présence d’autocorrélation.
[7] Dans l’hypothèse où les statistiques LM (Lag) et LM (Error) seraient toutes les deux significatives, il serait alors nécessaire de considérer les versions robustes de ces deux tests.
[8] La présence d’hétéroscédasticité, révélée par le test de Koenker-Bassett, pouvant être liée à celle de l’autocorrélation (Anselin 1988), nous considérons dans un premier temps le problème de l’autocorrélation.
[9] Pour effectuer ce test, des estimations récursives du modèle 1 sont effectuées afin d’obtenir une série de résidus standardisés qui permettront d’estimer l’équation suivante : $$$ \hat e = \alpha + \beta \, pat81 + \mu$$$. La statistique du test de Fisher est : $$$F=\frac{\left(\sum\hat{e}^{2}-\sum\hat{\mu}^{2}\right)}{\sum\hat{\mu}^{2}}\tfrac{q}{p}$$$, avec $$$p$$$ le nombre de coefficients à estimer et $$$q$$$ le nombre d’observations moins $$$p$$$.
[10] $$$n$$$ est un nombre suffisamment d’observations pour effectuer la régression.
[11] La répartition des régions dans chacun des deux groupes apparaît dans le tableau de l’annexe A.3.
Droits et Permissions
Accès libre (open access) : Cet article est distribué selon les termes de la licence internationale Creative Commons Attribution 4.0.
Le financement du libre accès est assuré par le BETA – Bureau d’Économie Théorique et Appliquée.
Du / des même(s) auteur()s
- La crise de COVID-19 est une opportunité pour développer le capital humain numérique en Europe, Claude Diebolt
- Les politiques ont-ils réellement tiré les leçons de la crise de 1929 ?, Claude Diebolt, Antoine Parent, Jamel Trabelsi
D'autres articles qui pourraient vous intéresser
- Grand angle sur l’année 2000, Michel Dévoluy
- La convergence constitue-elle le seul critère d’évaluation de la politique européenne de cohésion économique et sociale, René Kahn
- L’Espace européen de la Recherche et la politique régionale, Jalal El ouardighi, Jean-Alain Héraud
- Processus de convergence dans les pays d’Europe centrale et orientale : quels délais ?, Alexandre Sokic
- Critères de convergence, déréglementation du marché du travail et performance économique des régions européennes*, Florian Grosset, Roberto Martino, Phu Nguyen-Van
- L’Union européenne est-elle toujours au service du défi de la convergence ?, Benoit Dicharry, Jeremy Hamm
- La politique de cohésion de l’UE et la convergence économique, Benoit Dicharry, Phu Nguyen-Van, Thi Kim Cuong Pham
- Convergence ou divergence des politiques sociales ?, Isabelle Terraz